I posted here a while back on using GitHub with Visual Studio 2010. It was a fairly involved process using a third party plugin. Well now you can integrate with GitHub directly from Visual Studio, and it’s much, much easier. I used it yesterday to make my DataAnnotationValidator (blogged about here) available on GitHub for anyone who wants to use it – and, hopefully, so I can collaborate with others on developing it.
Although GitHub integration is now easier, it’s still a trek through unfamiliar and somewhat confusing screens, so I thought it might be helpful to put together a beginner’s guide to working with GitHub and Visual Studio 2013.
First things first – if you’re not already a member, join GitHub. Then you’re ready to begin. I happen to need to put together a little Web Forms / DynamicData demo for a customer, so I’m going to use that project as my example (and then take it down again so I don’t clutter up my GitHub page) .
I created an ASP.NET Web Application and ticked the ‘Add to source control’ box.

Then I chose Web Forms and got rid of authentication as I don’t need it for the little demo I’m putting together.

The next screen asks you what kind of source control you want. Obviously enough, the answer for us is Git:

Now you want to click on the Team Explorer tab under Solution Explorer.

That takes you to the following view and encourages you to download the command line tools. I’ll leave that up to you and focus on the Visual Studio integration:

Now it’s time to setup what’s going to be stored on Git, and what isn’t. I see no point in storing the external packages, so I want to exclude them. Click on the Changes option and you see an interface which initially assumes everything is going to be stored on Git:

I selected the packages folder, right-clicked and chose exclude:
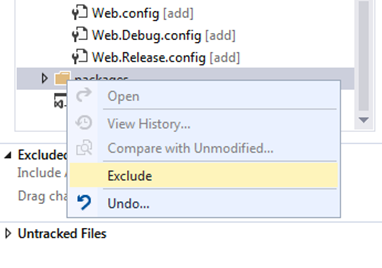
So now I have a list of included and excluded changes:

It’s time to enter a commit message and then click Commit… Except that you need to set up your email address and user name first:

Click on the Configure link and it takes you to a screen where you can enter your details. Notice, it also includes a couple of ignore rules for Git-related files:

So with that set up, we can fill in a commit message and commit our changes.

This commits them to our local repository, so we’ll get a dialog re. saving the solution:

And now we’re finally ready to sync with Git:

We click on the link to go to the Unsynced Commits page, and enter the URL of our destination repository:

Except we don’t yet have a repository on GitHub. So next we need to open up a browser, go to GitHub, sign in and click on the Add | New Repository link.
I created a DynamicDataGitDemo public repository (as you have to pay for private ones, and I’m only really interested in GitHub for open source projects). I also chose not to add a ReadMe or a license just yet, as we want an empty repository for Visual Studio. We can always add a ReadMe and license later on.

And finally we have a repository and we’re ready to upload our source code:

For that, we need the https link that’s available on this screen (and later, elsewhere in the interface).

So we copy that into Visual Studio and then press Publish:

Which, not unsurprisingly, brings up a dialog asking us to provide our credentials (which we won’t have to do again if we allow it to remember them):
And that’s it. Enter your GitHub username and password, click OK, and your source code is saved to GitHub.
From that point on, you can push changes up from your local repository, or pull down changes from GitHub. On my DataAnnotationValidator project, I added a ReadMe file and a license via GitHub’s browser interface (the latter as a text file, as the tool only generates one on initial creation) and then used Visual Studio to pull them down to my local repository, as well as subsequently adding changes locally and pushing them back up.
Overall, it’s a lot less fiddly than it used to be – as are so many other things inside VS 2013.
For other related information, check out these courses from Learning Tree:































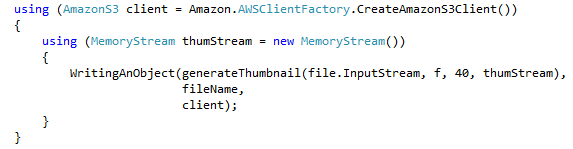
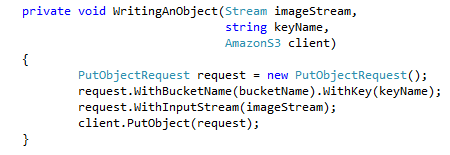 :
: