I recently had a customer request to add a Contact Us form to their DNN installation. It’s something I hadn’t done for a while. In fact, it’s been so long that the language has changed. Last time I played around behind the scenes on DNN (or DotNetNuke as it then was), the language was VB only – this time, the installation is C#. It turned out to be a lot simpler than it was back then, and also gloriously easy to add captcha – another of the customer requirements, as they’re tired of receiving spam from online forms.
I’m guessing that this is something a number of the readers of this blog might need to do some time, so I thought I’d share the easy way to build a DNN form module that includes a captcha.
Getting DNN to Create the Module
The first step is to get DNN to create the Module for you. You’re going to do this twice – once on your development machine, and again on the live site.
I ran the development copy of the site from Visual Studio 2012 and logged in as the host. Then I did the following:
- Go to Host | Extensions

- On the Extensions page, select “Create New Module”

-
In the dialog, there will initially be a single dropdown for “Create Module From”. Select “New”

-
This will then open up more fields, and allow you to get DNN to do the hard work for you. You want to
- Define an owner folder – in this case I went with my company name as the outer folder
- Create a folder for this specific module – I’m creating a contact us form, so ContactUs seemed like a sensible name
- Come up with a name for the file and the module – I went with Contact for both, to distinguish the Contact module from the ContactUs folder.
- Provide a description so you’ll recognize what it is
- Tick the ‘create a test page’ option so you can check everything was wired up correctly

You can now close your browser and take a look at the structure DNN has created. We have a new folder structure underneath DesktopModules – an outer Time2yak folder, and a nested ContactUs folder, complete with a Contact.ascx file:

If you open the web user control in the designer, this is what you get:

That’s given us a good starting point – but the first thing we’re going to do is delete the Contact.ascx user control. Just make sure you copy the value of the inherits attribute from the DotNetNuke.Entities.Modules.PortalModuleBase directive at the top of the ascx page before you delete it:

Creating the Web User Control
Now we’re going to create our own user control with a separate code behind page.
- Delete Contact.ascx and then right click on the folder and create a new Web User Control called Contact. This will recreate the ascx file, but this time with a code-behind file

- Change the definition of the code behind file so that it Inherits from DotNetNuke.Entities.Modules.PortalModuleBase (which is why you copied it).
- Now all you need to do is code the user control to do whatever you want it to do, just like any other ASP.NET Web Forms user control. I added a simple contact form with textboxes, labels, validation etc.:

-
I then used DNN’s built in Captcha control. It’s easy to use, provided you don’t mind working in source view, rather than design (actually, I prefer source view, so this works well for me). You just need to
-
Register the Control

-
Add it to the page

- Check the IsValid property in the code behind (note the use of Portal.Email to get the admin email address).
-

Import the Module to the live site
This is the easiest part of all. Just use the same steps to create the module on the live server that you did in development, and then copy your version of contact.ascx over the version on the live site. You now have the module in place and it appears in the modules list and can be added to any page you want:

And when you add it to the page, you have a Contact Us form with a captcha, developed as a DNN module:

The only other step is to use DNN to create the ThankYou.aspx page that the form passes through to – and that’s just a matter of using the CMS and doesn’t involve any coding.
For other related information, check out these courses from Learning Tree:





 :
:





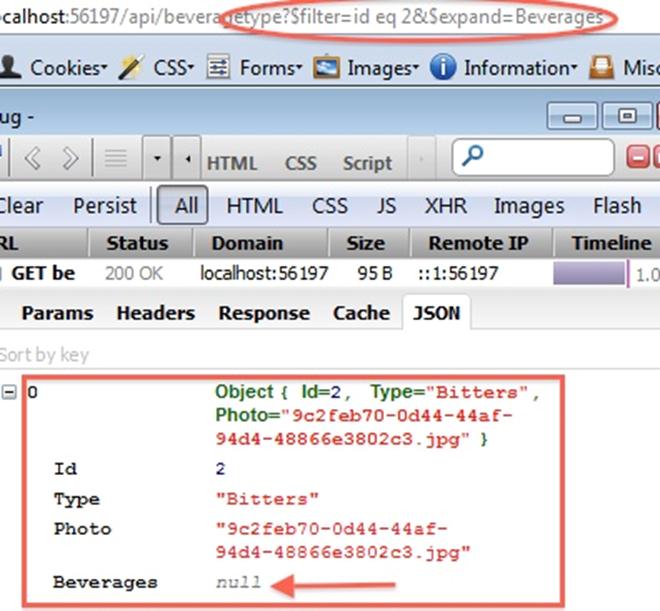

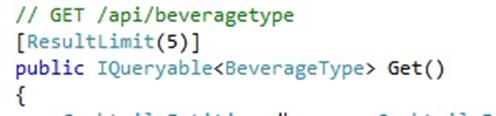
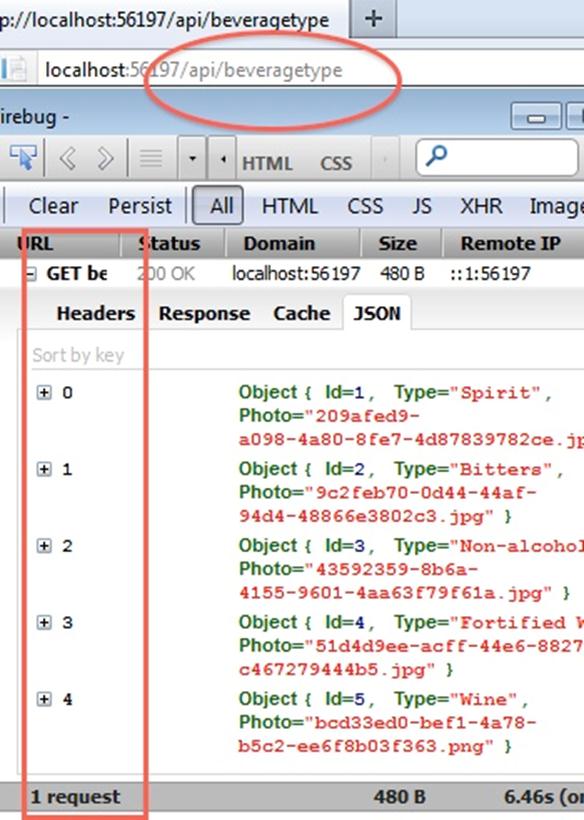
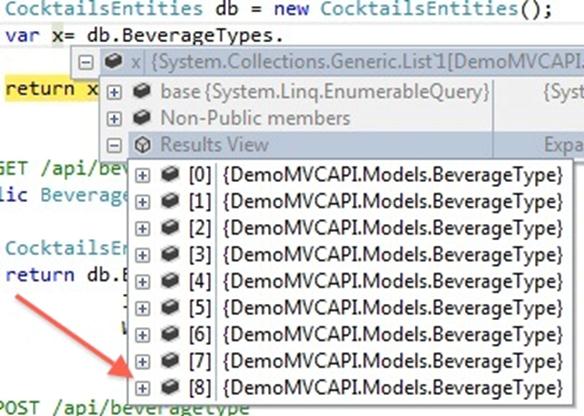




 :
: